AI projects often look perfect in a demo. The model scores well, the notebook is clean, and the slide deck has a crisp ROC curve. Then production hits. Retraining fails, features don’t match, costs spike, and nobody trusts the metric on Monday morning.
When that happens, the model usually isn’t the real problem. The problem is the AI-ready data architecture underneath it. If the data is hard to find, hard to join, and hard to explain, your “smart” system turns into a brittle system.
I don’t start with tools. I start with the business use case, then I map backward to the data, then to the platform and ops work. That order matters. AI success is designed, not bolted on. This guide is production-first and vendor-neutral, based on patterns I’ve seen hold up when the hype wears off and the pager stays on.
What “AI-ready data architecture” means in production
In production, AI-ready doesn’t mean “we bought a big platform” or “we have a data lake.” It means I can ship models and AI features that behave the same way tomorrow as they do today. It means I can explain outputs, reproduce training data, and update logic without breaking ten other things.
Here’s how I define AI-ready in plain terms:
- Stable training and scoring data: the same inputs produce the same features, with time handled correctly.
- Trustworthy metrics: dashboards and model labels match, and leadership stops arguing about whose number is right.
- Fast iteration: I can add a feature, rerun a backfill, and validate impact without a two-week data hunt.
- Clear ownership: someone is on the hook for data quality and meaning, not just pipeline uptime.
- Cost control: I can predict spend, set budgets, and stop runaway queries and reprocessing.
The trap is thinking AI readiness is a single milestone. It’s closer to safety rails on a highway. You build guardrails once, and every future project gets cheaper and less risky.
Centralized, queryable data with clear ownership
The minimum bar is simple: there’s one place to find curated data, with consistent access paths. That can be a warehouse, lakehouse, or a hybrid. I don’t care which, as long as the rules are clear and teams don’t build their own shadow copies.
Ownership matters just as much as storage. I like “data product” thinking, explained without ceremony:
- Who owns it (a named person or team)
- What it’s for (key use cases and KPIs it supports)
- How it’s used (tables, freshness, SLAs, access rules)
A short example of what breaks when ownership is unclear: marketing defines “active user” as “logged in once in 30 days,” product defines it as “completed a core action,” and support uses “opened the app.” Your churn labels drift, your retention dashboard fights your training set, and every experiment becomes a debate about definitions instead of outcomes. If I can’t answer “who owns this table and what does it mean” in 30 seconds, I don’t call the architecture AI-ready.
Consistent schemas, time-aware data, and reuse across BI and AI
Production AI punishes sloppy time handling. Late events arrive, backfills happen, customers change plans, and definitions evolve. If schemas and time logic aren’t consistent, you get silent errors that look like model drift.
I design for:
- Schema consistency: stable column names, types, and keys across domains. Changes are versioned, not snuck in.
- Time awareness: event time vs ingest time is explicit, slowly changing dimensions are modeled, and backfills don’t corrupt history.
- Reuse across BI and AI: the same curated tables should power dashboards and training sets.
Concrete example: “revenue by day” must match across BI and training. If finance sees $1.2M on Tuesday but the training set sees $1.05M, your model learns from a different reality than the business runs on. That mismatch shows up later as failed forecasts, bad targeting, and zero trust. When I’m forced to choose, I optimize for correctness over convenience. Speed is useless if I’m shipping confident nonsense.
Ingestion patterns that scale: batch, streaming, and why most teams need both
Most teams end up with both batch and streaming, even if they start with one. The goal is not to pick the fanciest pattern. The goal is to match latency and reliability to the use case, with the simplest ops burden possible.
I evaluate ingestion patterns on four axes:
- Cost: compute, storage, vendor fees, and reprocessing overhead
- Complexity: failure modes, schema evolution, and on-call load
- Latency: minutes vs hours, and whether the business truly needs it
- Reliability: reconciliation, exactly-once illusions, and how you recover
If the use case is weekly forecasting, real-time pipes add cost and new ways to fail. If the use case is fraud detection, batch-only will be too slow. I pick the simplest path that meets the user need, then expand when the need is proven.
Batch ingestion for ERP, finance, and history that must reconcile
For ERP, billing, HR, and finance systems, I default to batch. These sources care about reconciliation, not sub-second freshness. Batch pipelines are also easier to operate and budget.
Two common batch patterns:
- CDC (change data capture) when you need row-level history and incremental updates.
- Scheduled extracts when the system is stable and the tables are small enough.
In production, backfills are not “edge cases.” They’re normal. So I require idempotency (re-running doesn’t double count) and reconciliation checks that catch drift early.
Before I call a batch pipeline production-ready, I require this checklist:
- Clear primary keys and dedupe rules
- Load is idempotent (upsert or partition overwrite with safe keys)
- Backfill plan (how far back, how often, and who approves)
- Reconciliation checks (row counts, totals, and key financial aggregates)
- Documented SLAs and an owner for failures
Batch is also where cost discipline is easiest. Predictable schedules and bounded recompute windows keep budgets sane.
Streaming ingestion for events, telemetry, and operational signals
Streaming pays off when the value of freshness is real: user behavior events, telemetry, agent actions, and operational alerts. I use it when minutes matter and I can justify the added failure modes.
The common streaming failures are boring and painful:
- Out-of-order events that break time windows
- Duplicates that inflate counts and poison labels
- Schema drift that silently drops fields or breaks consumers
The controls that work are also boring:
- Stable event keys and consistent partitioning
- Watermarks and windowing based on event time
- Dead-letter queues for poison messages
- Contract tests for schemas, plus alerting on drift
A practical rule: if the business can live with 5 to 15 minutes of delay, I often stop at micro-batch. It’s simpler to replay, easier to reconcile, and usually good enough for dashboards and near-real-time scoring.
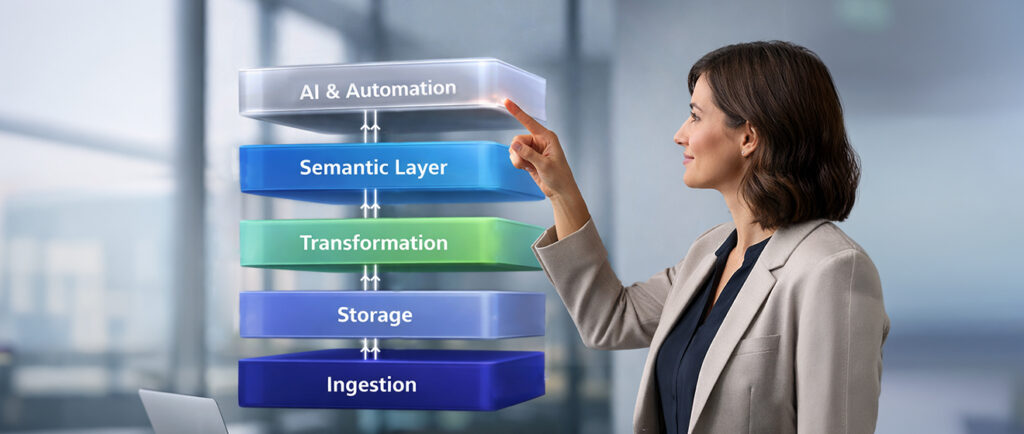
Architecture choices that hold up: warehouse, lakehouse, semantic layer, and a place for vectors
I don’t think of architecture as a single box. I think of it as a set of contracts: where data lands, how it’s curated, who defines metrics, how access works, and how AI consumes it. Tools change. Contracts should not.
Warehouse vs Lakehouse: when each is enough, and what usually forces the switch
A warehouse works well when data is mostly structured, reporting needs are clear, and governance is strict. It’s often the fastest way to get reliable BI and shared tables. For many companies, that’s enough for years.
A lakehouse becomes attractive when:
- You have mixed formats (JSON events, logs, images, or parquet data from partners).
- Data science needs larger volumes and more flexible compute.
- Storage economics matter, and you want cheaper retention for raw and semi-raw data.
- You need more control over file layout, partitions, and open table formats.
The trade-off is operational overhead. With more flexibility comes more ways to misconfigure performance, permissions, and lifecycle rules. If I adopt a lakehouse pattern, I’m strict about tiering data (raw, staged, curated) and about who can write to curated layers.
Many teams run a hybrid and that’s fine. The key is to make the boundary clear: what is “source of truth,” where business logic lives, and how data moves across the line without creating two competing realities.
The semantic layer: keep business logic out of dashboards and notebooks
If KPI logic lives in dashboards, every dashboard becomes its own definition engine. If feature logic lives in notebooks, every model becomes a one-off. Both patterns scale badly.
A semantic layer is where I put shared business meaning:
- Metric definitions (revenue, churn, activation, margins)
- Dimensions and join rules (customer, account, product)
- Access rules (who can see what, at what grain)
- Default time logic (time zones, fiscal calendars, late event rules)
This helps AI more than people expect. Models need consistent labels, consistent aggregates, and consistent slices for evaluation. If “churned customer” is defined one way in BI and another way in training, you don’t have an ML problem. You have a definition problem.
I want the same definitions powering dashboards, training sets, offline evaluation, and post-launch monitoring. One definition, many consumers.
Leave room for a vector database so GenAI and agents don’t become a side project
GenAI features often die because they are built as a parallel stack. Someone scrapes docs, makes embeddings, and ships a demo chatbot. Six weeks later the content is stale, access control is wrong, and nobody owns refresh. The simple pattern I use is: curated data stays in the warehouse or Lakehouse, then I create embeddings from curated slices and store them in a vector database for retrieval.
A concrete use case: support articles, policy text, product catalog copy, and internal runbooks. With retrieval, a support agent can get grounded answers with citations, and a customer-facing assistant can reference current policies.
The caution is blunt: don’t vectorize raw junk data. If you embed unreviewed tickets, half-written docs, and random exports, you get confident nonsense faster.
For vectors to work in production, I plan for:
- Refresh cadence (daily, hourly, or on publish events)
- Metadata (source, version, timestamps, access tags)
- Access control (role-based filters at query time)
- Evaluation (answer quality checks, drift checks, and feedback capture)
This keeps GenAI and agents inside the same governance model as the rest of data.
How I design for analytics and AI together, with governance built in
I treat analytics and AI as two consumers of the same curated foundation. If they need separate pipelines to “move faster,” that speed is fake. It turns into duplicated logic, mismatched numbers, and painful audits.
I start with a single high-value use case, then map the data path end to end:
- What decisions will this system support?
- What data is needed, at what grain, with what latency?
- What is the label or target, and who approves its definition?
- What are the failure modes, and how do we detect them?
Reusable transformations and feature tables that stay correct over time
Feature reuse is one of the fastest ways to reduce ML cost. If every model computes “last-30-day spend” differently, you’ll spend your life debugging, not shipping. I build shared transformations and feature tables with point-in-time correctness. In plain language: when I compute a feature for a past date, it must only use data that was available at that time. Otherwise, the model trains on future knowledge and fails in production. This is where training-serving skew happens. It’s not mysterious. It’s usually a mismatch in joins, time windows, or filters.
Example: a churn model uses “support tickets in the last 14 days.” In training, you accidentally include tickets that were created after the snapshot date because your join uses load time, not event time. The model looks great offline and falls apart when scoring daily.
I avoid this by sharing the same transformations for training and scoring, with explicit time keys and tested windows.
Governance that supports production AI: access, lineage, audit logs, and human checks
Governance shouldn’t be a roadblock. It should reduce rework and risk.
The minimum governance set I bake in:
- Role-based access by domain and sensitivity (PII, finance, HR)
- Lineage so I can trace a feature or metric back to sources
- Observability for freshness, volume shifts, and failed runs
- Audit logs for regulated work and incident response
Some AI systems also need human checks. If an agent can issue refunds, change entitlements, or send outbound messages, I add approval steps and feedback capture. I want a clear record of actions, inputs, and who approved what.
Lightweight governance beats “trust me” every time.
A conceptual reference architecture, plus the anti-patterns that kill scale
My reference flow is straightforward:
Ingestion (batch and streaming) feeds raw storage, then curated transforms produce domain tables, the semantic layer defines business meaning, and AI workloads consume curated features plus vectors where needed. Orchestration, monitoring, and cost controls wrap the whole system.
The anti-patterns that kill scale show up in almost every failing program:
- Dashboard-driven pipelines: logic gets trapped in BI tools, then models can’t reuse it.
- Hard-coded business logic: definitions change, code doesn’t, and trust collapses.
- Point-to-point integrations: each new use case adds another fragile connector.
- No cost visibility: spending grows, then projects get cut at the worst time.
- Ignoring data drift and quality: models degrade quietly until users give up.
If I fix these early, the architecture keeps paying dividends.
Conclusion
When AI fails in production, it’s rarely because the team can’t train a model. It’s because the data path is unstable, definitions conflict, and nobody owns the messy middle. A real AI-ready data architecture is a set of practical contracts: clear ownership, time-correct curated tables, batch plus streaming where it fits, sane platform choices, a semantic layer for shared meaning, and governance that supports shipping.
AI success is designed, not bolted on. If you want momentum that lasts, pick one high-value use case, map the data path end to end, then fix the foundation once so analytics, AI, and automation all benefit.
Need a data architecture consultation? Book one now for free.