
Many teams think moving to the cloud equals Data Platform Modernization. The logic sounds simple: lift the warehouse, rebuild a few pipelines, call it done. That’s just legacy tech on someone else’s computer. True modernization is less about where your data lives, and more about how fast it becomes useful and how safely you can change the system. Two ideas matter most:
1) Latency: how quickly data becomes usable for decisions, analytics, and AI.
2) Decoupling: breaking big, fragile systems into parts that can change without breaking everything.
Modernization is architectural, not geographical. If you only relocate a monolith, you keep the same constraints. If you reduce latency and decouple components, you change how the business operates. Latency is a competitive advantage. This article uses a simple before vs after lens, then shows how modernization shifts the data org and business results.
What a conventional data platform looks like in real life (and why it slows teams down)
Conventional platforms often work fine for finance close or monthly reporting. Problems start when the business needs faster feedback loops. Product teams want same-day cohort analysis. Ops teams want fraud signals before losses pile up. AI teams want features that reflect what just happened, not what happened yesterday. In many enterprises, the “before” state has a familiar shape:
Nightly batch jobs run after midnight. Data lands in a warehouse with heavy pre-processing. If a job fails, someone wakes up to fix it, because dashboards will break by 9 a.m. Access follows a ticket system since the data team owns the pipelines, the warehouse, and the meaning of metrics.
The technical traits create business drag:
1) Slow cycles: a small metric change waits days behind other requests.
2) Hidden risk: one upstream tweak can break a dozen reports.
3) High support load: engineers spend time restoring service, not improving it.
4) Weak AI outcomes: training data arrives late, labels lag, and features drift.
When data arrives late, teams stop trusting it. When teams stop trusting data, they stop using it.
Monolithic ETL and tightly coupled jobs that break on small changes
Legacy ETL often transforms data before it lands inside a few giant workflows. Over time, those workflows become “do everything” pipelines. One job handles ingestion, joins, cleaning rules, and business logic. Then it publishes a curated table that everyone depends on.
A single schema change can trigger a chain reaction. A column rename breaks downstream reports. A new event type changes row counts, and anomaly alerts fire for the wrong reason. Testing takes a long time because the workflow touches many systems. Rollbacks are painful because the pipeline rewrites data in place.
Business impact shows up fast: incident bridges, delayed releases, and cautious teams. People learn to avoid change because change causes outages. That fear becomes technical debt, and the debt keeps compounding.
Batch latency and stale dashboards that make decisions late
Batch latency is the quiet tax you pay every day. Data collected at noon will become visible tomorrow morning. Leaders make calls on yesterday’s reality. Teams react to problems after customers already feel them. Operational use cases suffer the most. Fraud detection needs fresh patterns. Inventory decisions need current demand signals. Customer support needs context from the last session, not the last day.
AI cannot succeed in stale data. Models can still train, but features fall behind behavior. The result is a system that looks smart in a lab, then disappoints in production.
Siloed access turns the data team into a ticket queue
Conventional platforms push every request through a central team. Someone asks for a new dataset, a new metric, or a new permission. The data team becomes the gatekeeper, because governance feels safer that way. Meanwhile, business teams still need answers. So, they create shadow copies in spreadsheets, departmental databases, or exported extracts. Metrics drift because each group defines “active customer” differently. Security risk rises because copies spread beyond controlled zones.
The org loses agility twice: once from waiting on tickets and again from debating which number is real.
Also Read: What Are Data Quality Metrics and Their Dimensions?
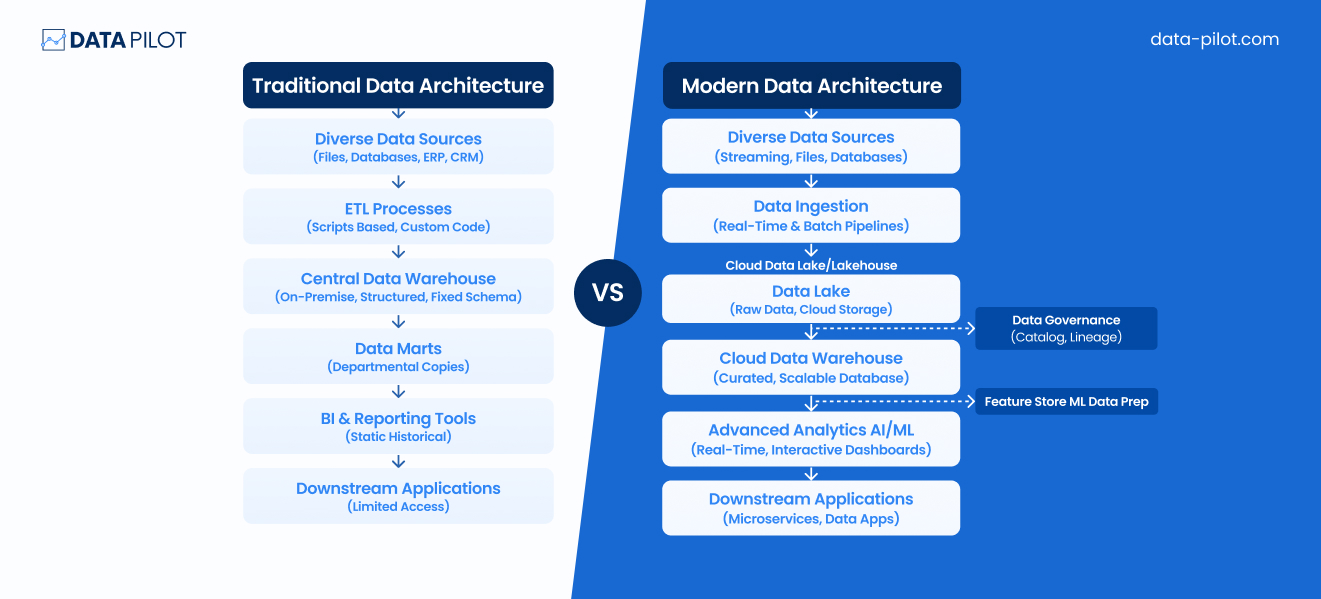
What changes in a modern data platform (it is less about tools, more about architecture)
Modern data platforms can run on popular tools (Snowflake, Databricks, Kafka, dbt), but tools are not the point. Architecture is the point. The goal is simple: reduce latency and make change safe. In practice, modern architecture replaces brittle chains with clear layers and contracts. It separates raw ingestion from curated models. It treats transformations like software, with version control and tests. It also supports streaming or micro-batching where the business needs fast signals. Decoupling enables scale. When components have clean boundaries, teams can improve one part without stopping the whole system.
Before comparing the pieces, here is the core shift in one view:
| Platform trait | Conventional approach | Modern approach | Business effect |
| Change safety | Tight coupling, shared blast radius | Contracts, ownership, backward-compatible changes | Fewer outages, faster releases |
| Freshness | Overnight batches | Streaming or micro-batches where needed | Faster decisions, better AI features |
| Cost control | Fixed clusters, shared contention | Separate storage and compute, isolation | Pay for use, predictable performance |
The takeaway is simple: modernization improves speed and trust at the same time.
From ETL to modular ELT, ingest first and transform with version control
ELT flips the order. You ingest raw data first, then transform it inside the warehouse or lakehouse. That sounds like a small change, yet it unlocks better engineering habits.
Transformations become modular models, not one giant workflow. Teams can reuse common logic. They can test changes before they are released. They can review code and track lineage. A “dbt-style” workflow (plain SQL models with tests and builds) makes this approachable for many teams. Because transformations live in version control, releases get safer. If a change causes issues, you can revert cleanly. Over time, this shrinks the gap between analytics work and software delivery standards.
From overnight batches to streaming or micro-batching for near real-time data
Not every dataset needs millisecond latency. Finance reporting may remain daily. Still, many high-value use cases do need fresher data. That is where streaming and micro-batching fit. Event-driven pipelines capture changes as they happen. Change data capture (CDC) can stream database updates. A Kafka-class backbone can move events reliably between systems. Micro-batching can run every few minutes when full streaming is too complex.
Latency is a competitive advantage. It turns dashboards into operational tools and AI features into real-time signals. Two examples make this concrete:
1) Fraud alerts: streaming events can flag risky behavior during a session, not after settlement.
2) Pricing and supply chain: near real-time demand signals help adjust prices or replenishment before stock-outs hit.
Recent industry reporting also points to rapid growth in production AI usage (including a reported 210% rise in organizations putting AI models into production). That trend raises the bar for fresh, reliable data feeds.
Data contracts and clear ownership reduce breakages and firefighting
A data contract is a simple agreement: what a dataset contains, how it changes, and who owns it. Contracts define schema expectations, freshness targets, and quality checks. They also set rules for safe evolution, such as adding fields without breaking consumers. Ownership matters as much as the contract. When each dataset has a named owner, issues stop bouncing between teams. Automated checks catch schema drift early. Root cause analysis becomes faster because the system has clear boundaries and lineage.
The business result is fewer broken dashboards and fewer “all hands” incident calls. Teams spend more time shipping improvements and less time restoring service.
Decoupled storage and compute lowers long-term cost and reduces lock-in risk
Modern platforms often separate storage and compute. That means you can scale heavy queries without copying all data. It also means one expensive job does not slow everyone else, because workloads can run in isolated compute pools. Cost becomes easier to manage. You pay for the compute you use when you use it. You can also change components over time without rewriting the whole stack. That flexibility reduces lock-in risk and improves negotiation power. Modernization is architectural, not geographical. A cloud bill can still explode if you keep monolithic workloads and shared contention. Decoupling helps you control both performance and spend.
How modernization changes the data organization, and what leaders must do differently
Data architecture changes fail when the operating model stays the same. Many teams modernize pipelines, then keep running the org like a service desk. That mismatch creates frustration because the platform can move faster than the process allows.
Modern data platforms are productized infrastructure. Leaders need to treat the platform like an internal product with customers, roadmaps, and reliability targets. At the same time, they must push decision-making closer to domain teams, with clear guardrails. This does not require a dramatic reorganization. It requires a new set of habits: ownership, standards, and shared responsibility for quality.
From query desk and dashboard maintenance to platform architects and enablers
In the old model, data engineers spend days fixing broken reports, backfilling tables, and answering access requests. Their backlog reflects other teams’ needs, not a coherent platform plan.
In a modern model, a small platform team focuses on enabling work, not doing all work. They provide templates for ingestion, modeling, testing, and deployment. They build shared services like identity, catalog, and data access patterns. Domain teams then publish data products with clear contracts. Bottlenecks shrink because teams can ship changes without waiting in line. Engineers also regain time to improve performance, reduce cost, and strengthen reliability.
From firefighting to reliability: observability, data quality automation, and clear SLAs
Reliability means your data arrives on time, stays consistent, and remains understandable. It also means costs do not surprise you at the end of the month. Data observability helps by monitoring freshness, volume, schema changes, and lineage. Automated tests catch obvious issues before they reach dashboards. Clear SLAs (or SLOs) define what “good” looks like for key datasets.
Treat data like production software: test it, monitor it, and set clear uptime and freshness goals. When reliability improves, trust returns. When trust returns, teams adopt shared metrics instead of building shadow copies.
A practical modernization roadmap that avoids big-bang rewrites
Big-bang rewrites fail because they take too long and break too much at once. A better approach is incremental: modernize the highest pain first, then expand patterns that work. Use four phases, each with measurable goals. Track latency reduction, incident rates, deployment frequency, and time-to-access for new datasets. Those metrics connect technical progress to business outcomes.
Phase 1: Assess what you have, map pipelines, and find the biggest latency traps
Start with inventory. Map pipelines, dependencies, and top consumers. Identify where data waits, whether in queues, batch windows, or manual steps. Define freshness goals for key datasets and document current reality.
Next, run a technical debt audit. Look for fragile workflows, hidden business logic, and repeated transforms in multiple places. Then tie findings to business pain. Which revenue or risk use cases suffer most from stale data?
Pick 1 to 2 value streams for a pilot, such as fraud, inventory, or customer experience analytics. Keep the scope tight enough to finish in weeks, not quarters.
Phase 2: Decouple ingestion and transformation, then introduce modular ELT and data contracts
Separate raw ingestion from curated layers. Standardize naming, ownership, and access patterns. Then move transforms into version-controlled models with repeatable builds and tests.
Add contract checks early. Even basic schema and freshness rules reduce the blast radius of change. As a result, teams can ship updates more often, with fewer surprises.
A good target here is cutting incident volume and reducing time-to-fix for broken datasets.
Phase 3: Reduce latency with streaming or micro-batching for the use cases that need it
Upgrade freshness where it pays off. Prioritize events that drive decisions. Design pipelines for retries, idempotency, and late-arriving data. Those details prevent duplicate counts and broken features.
Update dashboards and AI features to consume fresher data. Otherwise, the pipeline improves but the business still sees yesterday’s outputs.
Hybrid patterns can help when data must stay on-prem for compliance, or when edge collection reduces network cost. The point is not “everything real-time”, it is “real-time where it matters”.
Phase 4: Operationalize with CI/CD for data, observability, and cost governance
Turn good patterns into standard practice. Add automated tests, deployment gates, and lineage tracking. Set alerts for freshness and schema drift. Put budgets and usage policies in place to prevent runaway spend.
Success looks like higher developer productivity and predictable cost. It also looks like faster AI experimentation, because teams can trust inputs and iterate quickly.
Conclusion: Modernization pays off when speed and safety improve together
Cloud migration alone is not Data Platform Modernization. If the architecture stays monolithic and batch-bound, the business still waits. Real modernization focuses on latency and decoupling, because Latency is a competitive advantage. Decoupling enables scale. In the next 30 to 60 days, focus on actions that create momentum:
1) Pick one high-value pipeline where stale data costs real money.
2) Define freshness goals that match the business decision window.
3) Add data contracts and ownership for the datasets in that flow.
4) Set up observability so failures surface before leaders notice.
Data Pilot can be the implementation partner that makes this real: discovery and assessment, architecture and roadmap, hands-on delivery (ELT patterns, streaming where needed, contracts, CI/CD, observability), plus enablement so your internal team can run it long-term.